If you already have a Hive metastore, such as the one used by Azure HDInsight, you can use Spark SQL to query the tables the same way you do it in Hive with the advantage to have a centralized metastore to manage your table schemas from both Databricks and HDInsight.
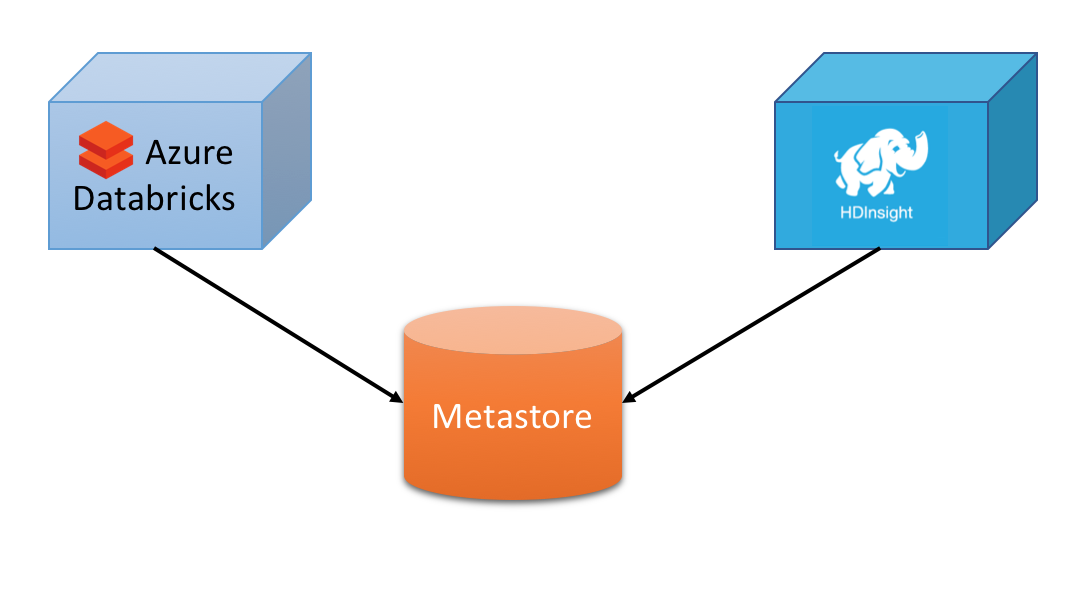
There are a couple of options to set up in the spark cluster configuration.
Apart from the database configuration options you need to specify the hive metastore version, for the current HDInsight version this is 2.1.1, and make sure to set hive.metastore.schema.verification.record.version and hive.metastore.schema.verification to true to make sure that the Spark cluster doesn’t update the metastore schema.
Also you will need to give access to the right Azure Storage account/s in order to have the right permissions to access the underlying physical data (remember that metastore is only that, metadata, not the actual data).
1 | spark.hadoop.javax.jdo.option.ConnectionDriverName com.microsoft.sqlserver.jdbc.SQLServerDriver |